当你设置好服务器投入使用后,你最关心的事莫过于服务器的性能了。你可以用一些手动的方法进行测试,但手动方法有很多局限性。
先不论手工测试方法所投入的时间和精力问题,用手工方法测试的一大不足就是它不容易揭示出你的站点的真正问题所在,是服务器设置的问题还是因为一些动态组件又或是网络基础设施造成的问题?
幸运的Apache HTTP工程包含了一个名为HTTPD-Test的子工程,正如这个名称所揭示的,这是一个Apache的通用测试工具包,这个包里包含了大量的不同工具,而本文将主要介绍其中一个名为洪水(Flood)的工具,它之所以如此命名,是因为它利用向服务器发出洪水般的大量请求测试服务器的响应时间。
洪水使用一个XML文件来进行必要的测试设置,包括测试中使用的URL和POST数据和准备测试的服务器组,然后Flood开始测量以下一系统操作的时间:
●打开一个到服务器的socket
●向socket写入对服务器的请求
●读出服务器的响应
●关闭socket
当测试结束,管理员就可以了解到是否存在Apache服务器(或其它HTTP服务器)的设置问题,服务器的实际负荷,硬件的性能表现和是否存在着网络基础设置瓶颈。
安装Flood
你可以在Apache网站下载httpd-test和apr/apr-util软件包,后者是当从Apache的CVS服务器上直接build时所需要的。你必需先进行登录(密码是"anoncvs")
$ cvs -d :pserver:anoncvs@cvs.apache.org:/home/cvspublic login
$ cvs -d :pserver:anoncvs@cvs.apache.org:/home/cvspublic co httpd-test/flood $ cd httpd-test/flood
$ cvs -d :pserver:anoncvs@cvs.apache.org:/home/cvspublic co apr
$ cvs -d :pserver:anoncvs@cvs.apache.org:/home/cvspublic co apr-util
如果你取得了源码,你可以用下面的命令安装:
$ buildconf
$ configure
$ make all
现在,安装完成了。
设置Flood
Flood通过一个XML格式的设置文件来定义测试中使用的各种参数,我们不妨通过一个形象的比喻也说明一下Flood的工作过程和需要设置的各个方面。首先,Flood使用一个模型(profile)来定义一组给定的URL如何被访问,具体的访问由一个或多个农夫(farmer)来进行,而这些农夫又属于一个或多个农场(farm),我们来看一下下面这个示意图:
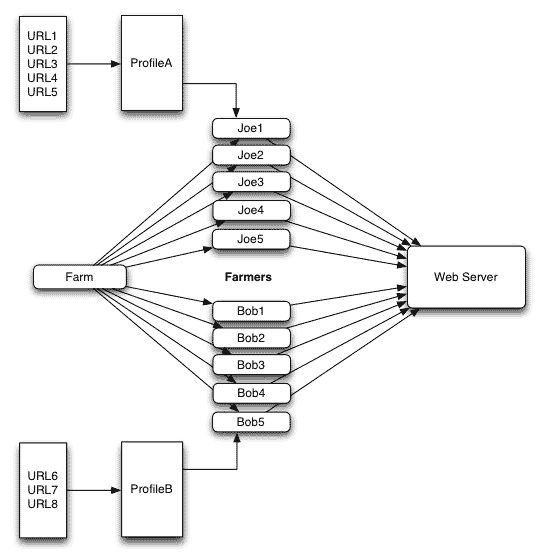
如图所示,现在我们使用一个农场,这个农场有两组农夫,其中农夫组Joe使用访问模型A与一个包含五个地址的URL列表,农夫组B使用访问模型B与一个包含三个URL的地址列表,这些家夫直接向WEB服务器请求列表中的地址。Flood使用线程来创建各个农夫,然后比较各个农夫收集到的数据并存入一个单独的文件以便之后做进一步的处理。
XML文件包括了这个测试需要定义的四个方面:URL列表,访问模型,农夫和农场。
URL列表也即一组即将被访问的地址的列表,这些URL地址可以被简单的引用进一步定义特定的请求方法(GET,POST,HEAD)。
访问模型定义测试使用哪一个地址列表,它们如何被访问,使用哪一种Socket,收集的信息如何被报告。
农夫负责实际的请求过程,对农夫唯一的可设置选项是使用哪一个访问模型和对一个访问模型的调用次数。每个农夫独立的执行自己的访问模型,但一个访问模型可以执行多次,因此最后的请求过程可能是这样:地址一、地址二、地址一、地址二、……。
对家场的定义涉及到创建农夫的数目和时间,通过增加一个家场创建农夫的数目,可以增加并发请求的数目。并通一些附加的设置,你可以设置一些初始数目的农夫,然后每隔特定的时间增加一定的农夫数量。例如,你可以开始创建两个农夫,然后每5秒钟增加一个农夫,直到农夫数目达到20时停止增加。这可以在一个给定的期间形成一个最大20的并发访问升级过程,然后又逐步将并发请求数降到0。另外也可以模拟这种访问情况,一定数目的访问者长时期的访问一系列页面,并操持最大并发请求数在5-6之间。
注意:到写这篇文章的时候为止,目前的Flood仅支持一个农场,而且它的名子必须是"Bingo",不过,通过为一个农场定义多个农夫,你可以取得同样的基本效果。
通过调节农夫,农场和URL列表的参数,你可以控制总请求数,并发请求数,测试时间(基于URL列表,重复次数和农夫的数量可以决定这一点),以及这些请求在整个测试期间的分布,这就允许你针对不同的条件订制你的测试。
在使用Flood进行测试设置时你应该记住的三个基本点是:
●地址列表定义了农夫们将访问的地址
●每个农夫的重复数目定义了一个用户访问你的站点的次数。
●一个农场的农夫数目定义了并发访问用户的数目。
在Flood发行包里的examples目录下有一个样例设置文件,round-robin.xml可能是一个最适合初学者学习的例子,不过本文并不准备就编辑此XML文件的规则或处理产生的数据文件做进一步的解说。
这里,我们主要想讲一下如何针对不同类型的WEB服务器来调整测试的参数。为了便于理解后面的内容,这里我们先看一下使用examples目录下的analyze-relative测试脚本得到的一个结果。在这个例子中,测试对象是一台内部服务器。
Slowest pages on average (worst 5):
Average times (sec) connect write read close hits URL
0.0022 0.0034 0.0268 0.0280 100 http://test.mcslp.pri/java.html
0.0020 0.0028 0.0183 0.0190 700 http://www.mcslp.pri/
0.0019 0.0033 0.0109 0.0120 100 http://test.mcslp.pri/random.html
0.0022 0.0031 0.0089 0.0107 100 http://test.mcslp.pri/testr.html
0.0019 0.0029 0.0087 0.0096 100 http://test.mcslp.pri/index.html
Requests: 1200 Time: 0.14 Req/Sec: 9454.08
在这里你可以看到测试中进行连接(connect),请求(write/request),回应(read /response),关闭连接(close)的平均时间。你也可以对服务器每称处理的请求数目有个基本的印象。
对于新闻类站点的测试
对于如New York Times、Slashdot之类的新闻站点以及一些BLOG之类,它们都有一个主要的首页,首页上有着众多到栏目页和内容页的连接,对某条信息感兴趣的读者可以点进去仔细阅读。
通常情况下,这类站点的首页访问量相对固定而对于其它页面,访问量的变化就会更大一些。如果它推出了RSS/RDF订阅服务,那么就会出现一定量的直接到内容页的流量而不经过首页。大部分的此类站点都使用了某种内容的动态化技术,而Flood是测试这类动态站点的一个不错方法,特别你可以将之与一些静态站的响应相对比。
你可以用以下的参数设置模拟对一个新闻类型的网站的访问:
| Farmer Set A | Farmer Set B | Farmer Set C |
URL List | Homepage Only | Homepage +3 stories | 3 story pages |
Repeat Count | 1 | 3 | 3 |
Count | 100 | 20 | 20 |
Start Count | 5 | 5 | 5 |
Start Delay | 1 | 5 | 5 |
Notes | Home page only | Homepage+Stories | Stories only (RSS) |
测试在线商店站点
在线商店,在线商品目录或其它一些更具交互性的网站则有不同的使用模型。虽然仍会有一部分人到达你的首页,一些人会直接进入你站内的某一个页面,大多数用户会在你的站里找来找去,他们可能会在一个产品页上浏览大量的产品,进行一些搜索或者点击进入一些相关的产品页面。
因此,你应该用更大数量的地址列表测试这类站点,更大的重复次数(以模拟大量的用户)和相对新闻类站点比较低的并发访问数目:
| Farmer Set |
URL List | 10-15 pages |
Repeat Count | 5 |
Count | 50 |
Start Count | 5 |
Start Delay | 5 |
测试 "Slashdot" 效应
有时,你必须测试你的系统能否应付某个特定时刻大量用户同时访问你的网站的情况。很多网站已经遇到过这个问题,一次重大事件中对于Slashdot网站的几个页面的引用就引发了对这个页面的巨量并发请求。
典型的情况下这些请求仅针对一个特殊的页面,我们可以通过在Flood中创建成百上千的家夫来并发请求服务器上的特定页面来模拟这种情况,通过设置高重复率和延迟系统来模拟一定时间内大量用户的连续访问。
| Farmer Set |
URL List | 1 page |
Repeat Count | 50 |
Count | 250 |
Start Count | 100 |
Start Delay | 1 |
测试技巧
为了让以上各类测试都工作得很好,你应该记住以下几点:
●最重要的是,不要直接在WEB服务器上用Flood进行测试,如果你这样做你仅仅是在测试一台机器打开一个网络连接与自己通讯的能力,一定要在另一台机器上进行测试。
●要对自己机器的一些技术限制有所了解,这包括你机器容许的最大线程数和最大网络连接数,如果你试图创建超过这个限制的农夫将会带来让人难以理解的测试结果。
●Flood是一个客户端解决方案,因此对于在多台机器上进行测试没有任何限制。事实上我们推荐你这样做,因为这是一个在想进行饱和性测试时避免你的客户机系统的技术限制的好方法。
●Flood测试由于是在客户机上运行,它的表现也要依赖于客户的性能,如果客户机系统处于繁忙的状态,Flood进程会与其它客户进程一样被阻塞,因此,最好使用一台专用的客户机进行测试,如果客户机上还运行着其它任务,在开始测试之前最好关掉它们。
(DVOL本文转自:中国DV传媒 http://www.dvol.cn)

