第一步
1、打开windows设备管理器。
2、查看-显示隐藏的设备
3、非即插即用驱动程序
4、NetGroup Packet Filter Driver 右键属性---驱动程序---启动类型,修改类型为“系统”
第二步: 在cmd下输入net start npf,打开网络抓包服务(Netgroup Packet Filter 网络数据包过滤器)
启动NPF的方法:
a. 以管理员身份运行命令行程序cmd.exe
b. 输入net start npf命令,确定后就会提示服务启动成功,如图:
这样的方式只能在这一次启动NPF服务,电脑重启之后又要重新启动,如果希望电脑启动时自动启用NPF服务,则可以在上面第二步将命令行换成
sc config npf start= auto。
第三步:
运行wireshark ,此时网卡已经可以正常检测到了
================
wireshark无法捕获无线网卡数据解决办法
总是出现 The capture session could not be initiated (failed to set hardware filter to promiscuous mode).
解决办法:Wireshark->Capture->Interfaces->Options on your atheros->Capture packets in promiscuous mode - SET IT OFF.
=================
win10支持的:
http://www.win10pcap.org/download/
教程精选:
https://www.cnblogs.com/lsdb/p/9254544.html
数据包详解:
https://www.cnblogs.com/strick/p/6261463.html
osi模型及tcp/ip模型数据包知识复习:
https://www.cnblogs.com/qishui/p/5437301.html
=================================
wireshark 数据包分析技巧总结
wireshark 过滤表达式的比较运算符一览 (类 C 形式和对应的英语形式)
enighish C-like 含义和实例
eq == 等于 ip.src == 10.0.0.5
ne != 不等于 ip.src != 10.0.0.5
gt > 大于 frame.len > 10
lt < 少于 frame.len < 128
ge >= 大于等于 frame.len ge 0x100
le <= 小于等于 frame.len <= 0x20
注意, ip.len le 1500 这里的 "ip.len" 含义是,从网络层分组的 IP 头部算起,加上传输层分段头部,加上应用层数据,
总长度小于1500字节,同理,"frame.len"需要从链路层以太网帧头开始计算;
默认情况下,wireshark 主界面最上方的数据包概况的 length 字段,计算的是从链路层以太网帧头开始计算的大小,我们可以
通过 ip.len , tcp.len , udp.len 等来指定从数据包的哪一层开始计算大小并显示
【常用的捕捉过滤表达式】
仅捕获来自或去往 192.168.1.0 网段中的数据包
net 192.168.1.0/24
注意,以 net 操作符开头的过滤表达式不支持显示过滤,仅支持捕获时过滤,并且只要是用于捕捉过滤表达式的关键字,都不能用于显示过滤表达式,反之亦然
仅捕获来自或去往 192.168.0.1 主机的数据包
host 192.168.0.1
仅捕获来自 192.168.0.1 主机的数据包
src host 192.168.0.1
仅捕获与 www.evil.com 的通信中,非 HTTP 协议以及非 SMTP 协议的数据包
host www.evil.com and not (port 80 or port 25)
仅捕获 TCP 协议,并且端口在 1501~1549 的数据包
tcp portrange 1501-1549
注意,关键字“portrange”仅支持 libpcap 0.9.1 以及更新版本,如果是 0.9.1 以前的版本,使用下面过滤表达式:
(tcp[0:2] > 1500 and tcp[0:2] < 1550) or (tcp[2:2] > 1500 and tcp[2:2] < 1550)
其中,
tcp[0:2] 表示从 TCP 分段头部(0)开始,长度为2字节(2)的字节序列,而这就是源端口号
tcp[2:2] 表示从 TCP 分段头部的第二个字节开始(2),长度为2字节(2)的字节序列,而这就是目的端口号
这种语法:
一,支持捕捉过滤与显示过滤
二,支持匹配 IP 分组头部,TCP分段头部,UDP 用户数据报头部,ICMP 网际控制消息协议数据包,以太网数据帧,以及其它多种格式的数据包头部结构中特定的字段(字节序列),
考虑如下过滤表达式:
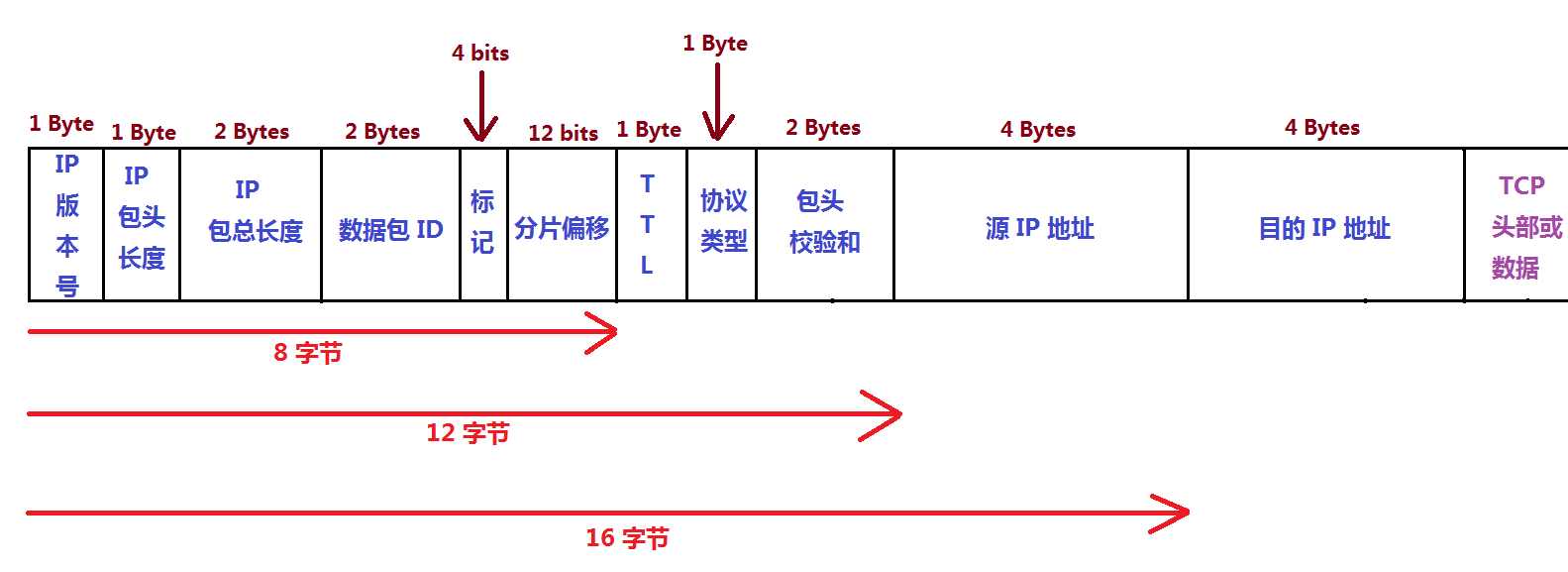
ip[8:1]==1
仅显示 IP 从分组头部的第八个字节开始(8),长度为1字节(1),其“值”为 10进制1 的数据包
查看相关 RFC 文档对 IP 分组头部结构的定义,其第九个字节为 TTL(Time To Live),这将会显示所有 IP 分组头部的 TTL=1 的数据包。
下图为 IP 分组头部结构,wireshark 的“中括号内数字加冒号”的表达式正是利用了这种结构中,“结构成员”的字节偏移(第N字节)与“结构成员”的长度:
为什么 TTL 的值如此重要?
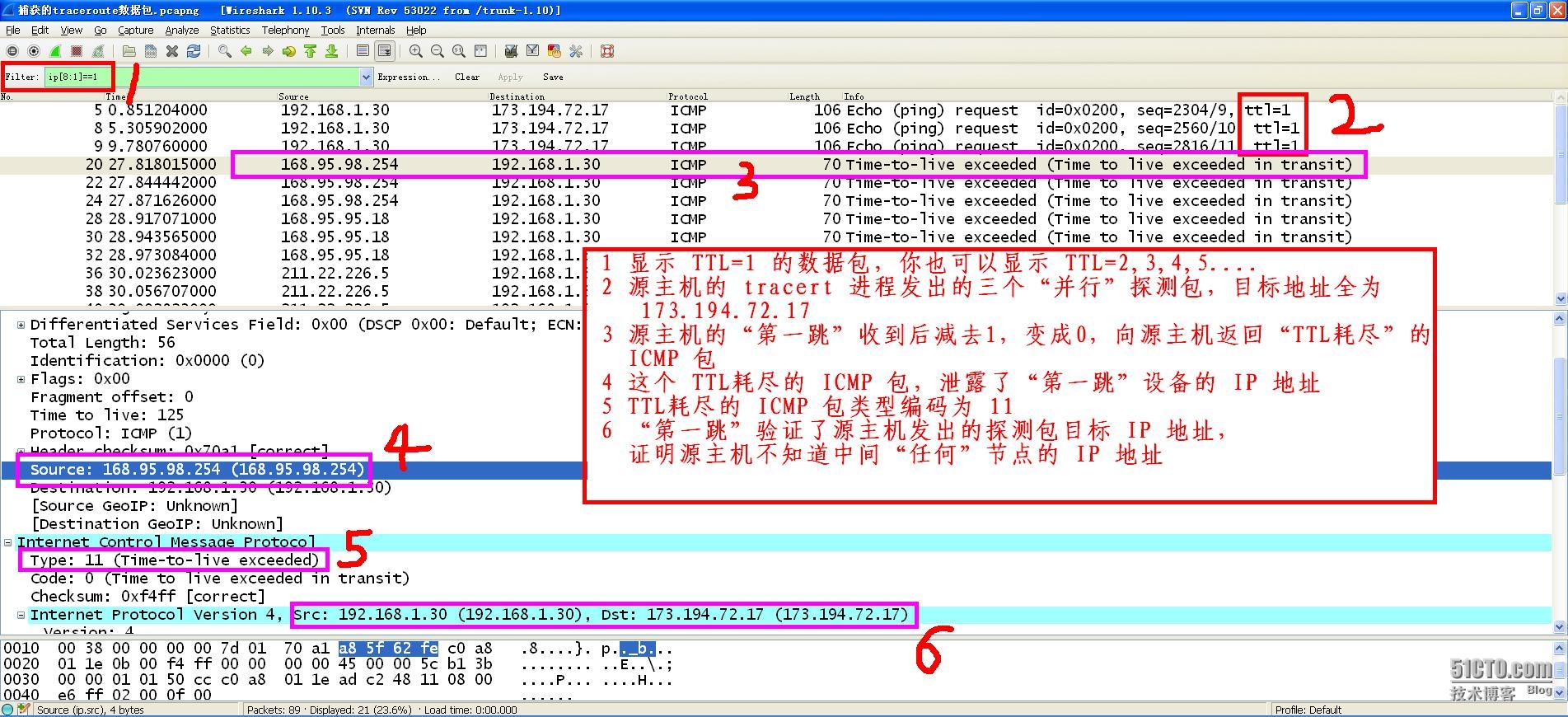
我们知道,UNIX / Linux 平台的 traceroute 工具,以及 windows 平台的 tracert 工具,用来检测并输出与指定目标之间,经过的所有网络设备或主机节点,
每经过一个节点,计算为一跳(hop),正常情况下,源主机发出的数据包,为了保证能顺利到达目的主机,其 TTL 值应该在 40 以上,因为中间经过的每个节点会将收到的数据包 TTL 值减 1,然后判断其值是否为 0,如果不为 0,则转发该数据包给下一跳,如果为 0,直接丢弃这个数据包,然后给源主机回送一个 ICMP 类型为11(Time to live exceeded in transit,传输中 TTL 值耗尽)的数据包,
注意,
一,这个回送的 ICMP 包,其 IP 头部的 TTL 值不可能为 1,至少也在40以上,否则当它被“前一跳”接收时,前一跳节点减去1后,判断其为0,则直接丢弃,那么这个通知 TTL值耗尽的数据包就不可能正确的回传给源主机
二,这个回送的 ICMP 包,其 IP 头部的源地址字段,就是这个节点自身的 IP 地址
tracert / traceroute 工具正是利用了上述这两个特性,向因特网上发出目标地址相同,但是每次 TTL 值 递增1 的数据包,它首先发出的数据包 TTL=1,然后接收到的第一个节点将其减 1 后判断,发现其为 0,于是丢弃这个数据包,向源主机返回 TTL 耗尽的 ICMP包,这个数据包的源地址字段,泄漏了第一个节点的 IP 地址给源主机上的 tracert / traceroute 进程,后者向屏幕输出相关 IP信息,
同理,源主机发出的第二个数据包 TTL=2,第一个节点收到后减 1,判断不为 0,于是转发给“下一跳”,第二个节点收到后减 1,判断为 0,丢弃,然后返回给源主机一个 TTL耗尽的 ICMP 包,其中带有第二个节点的 IP 地址,于是源主机上的 tracert / traceroute 进程继续向屏幕输出相关信息。。。。
多数情况下,地球上实际距离再远的两个主机,中间的节点数也不会超过 40,因此利用上述原理,tracert / traceroute 进程只需发出 10 或 20 个 TTL 分别为1~10 或者 1~20 的“探测”包,就可以向用户展示中间经过的所有设备列表
试想,我们运行 wireshark 的主机刚好位于第 5 个节点,那么源主机发来的 TTL=5 的探测包,将在经过前面 “4 跳”后,到达我们的主机上,其 TTL=1,于是 wireshark 的 ip[8:1]==1 表达式可以用来捕获探测本机是否存在的数据包,并且我们可以从捕获的这个探测包的源 IP 地址,查询到发出探测包的源主机的物理地址
当我们运行 wireshark 的 Linux 主机是作为源主机想要探测的目标的前端网关防火墙时,这点尤其重要:我们可以将 wireshark 捕获的 TTL=1 数据包的源 IP ,加入到 iptables 的入站链中并丢弃,或者设置成转发给我们后台的服务器,但是不向源主机回送 TTL 耗尽的数据包,避免泄漏我们的网关防火墙 IP 地址
回想一下你用使用 tracert / traceroute 的经验,是不是曾经碰到过,中间“某一跳”的 IP 部分为* * * 就是这个道理.
仅捕获“单播”流量,如果你只想捕获进出本机的数据包,使用下面的表达式可以帮助你排除本地网络中的“噪声”―――例如广播和组播通告:
not broadcast and not multicast
*****不要被下面这个看起来很复杂的表达式吓到,它的效果是仅捕捉使用 HTTP 的 GET 请求方法的数据包:
port 80 and tcp[((tcp[12:1] & 0xf0) >> 2):4] = 0x47455420
我们来分析一下这个表达式的语义,首先,port 80 指定 HTTP 协议,童鞋们应该都知道,
再来,HTTP 的请求方法是紧随在 TCP 头部后面的字段,其中,ASCII 字符的“G”,其16进制为 0x47,字符“E”的16进制为 0x45,字符“T”的16进制为
0x54,
在 HTTP 1.1 标准中,要求在方法名称后接一个“空格”字符,这个不可打印的空格字符,其16进制为 0x20,
于是我们知道,捕获 TCP 头部后面为 0x47455420 的4字节序列(GET加上空格字符共4字节),就等于捕获了 HTTP GET 请求数据包,
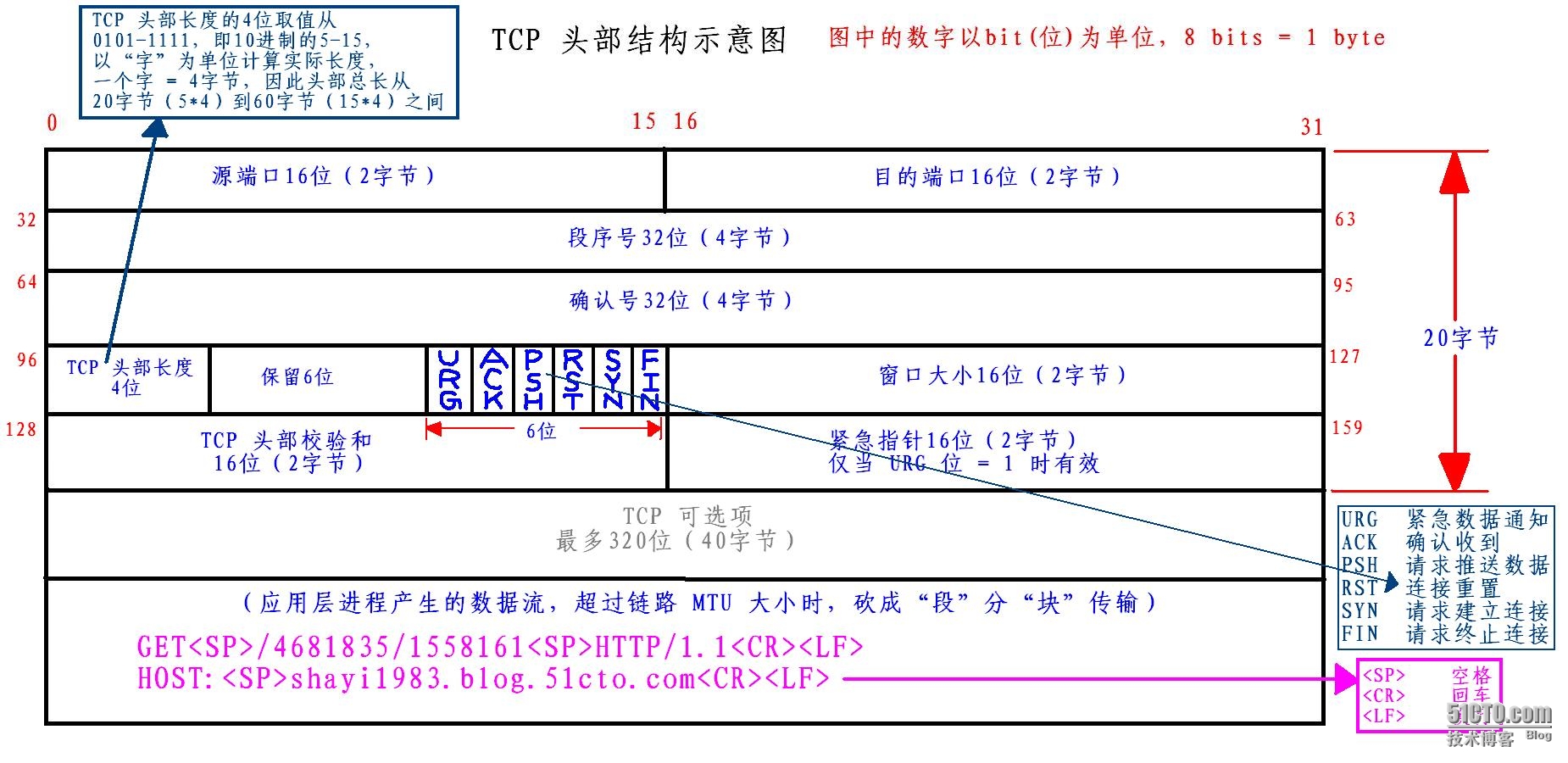
我们还需要知道 TCP 头部的长度为多少字节,这样才能定位16进制值的 “GET[space]” 字串的准确位置,
从每个数据包的 TCP 头部的第十三个字节开始,长度为4位(bit,比特)的半个字节(1 byte = 8 bits),给出了该数据包的 TCP 头部长度,因此,上面表达式中的 tcp[12:1] 部分,先获取 TCP 头部的第十三个字节(12+1=13),但是由于头部长度信息只保存在该字节的前面4位中,因此 (tcp[12:1] & 0xf0) >> 2 的作用就是扣掉后面的4位(这4位属于6位“保留位”中的前4位),计算出 TCP 头部的“净”长度,
得出 TCP 头部长度后,例如典型的20字节,那么从第二十一个字节开始,长度为4字节的字节序列,就是 HTTP 的请求方法,对应上面表达式的 tcp[((tcp[12:1] & 0xf0) >> 2):4] 部分
综上所述,
port 80 指定 HTTP 协议
tcp[((tcp[12:1] & 0xf0) >> 2):4] 定位 HTTP 请求方法 字段
0x47455420 指定 HTTP 请求方法为 GET[space]
对上面内容感觉头晕的童鞋,请参考下面的 TCP 头部结构示意图,这样就一目了然
下面这个表达式用来捕捉“冲击波”蠕虫病毒产生的网络通信流量,它利用的是 RPC 协议的漏洞:
dst port 135 and tcp port 135 and ip[2:2]==48
Welchia 蠕虫同样利用 RPC 协议的漏洞,但是我们有更好的检测这只蠕虫的捕捉表达式:
icmp[icmptype]==icmp-echo and ip[2:2]==92 and icmp[8:4]==0xAAAAAAAA
我们来分析一下该表达式的语义,它搜索长度为92字节的 icmp echo request
(ICMP 回显请求)数据包,而且该ICMP数据包的有效载荷起始部分为连续4字节长的16进制值0xAA,而这就是当Welchia 蠕虫尝试危害一个系统前的特征
*****许多蠕虫尝试通过与其它主机上的 135,445,1433 端口建立连接,来进行传播,
下面这则捕捉过滤表达式,可以检测绝大多数类型的蠕虫,因为它可以捕捉那些来自本地局域网中的目标端口为 135,445,1433 的 TCP SYN 数据包(请求连接,SYN 标识位的值不为 0 )
dst port 135 or dst port 445 or dst port 1433 and tcp[tcpflags] & (tcp-syn) != 0 and tcp[tcpflags] & (tcp-ack) = 0 and src net 192.168.0.0/24
是系统管理员或运维工程师的童鞋,可以用上面介绍的三则捕捉过滤表达式,来检测你的局域网中是否有机器感染了蠕虫病毒,而且正在尝试进行传播,感染其它机器
还有一件事需要注意,如果你用 SSH 远程连接到服务器(包括 Linux 下的 OpenSSH 以及 windows 下的 3389 终端),并且在服务器上运行 wireshark ,那么 wireshark 会通过检测“环境变量”来智能的过滤掉你与服务器通信的流量,这里过滤的意思是不显示或不捕捉,而非防火墙那样阻挡数据包;
下面列出这些 wireshark 可能会探测的环境变量,并且给出相应的“默认过滤”表达式;如果你想要 wireshark 在服务器上捕捉或显示你与服务器的远程通信流量,只需要将这些表达式中的 not 关键字移除即可,
其中,
*****粗体关键字 srcport srchost dstport dsthost
需要分别替换成你的 SSH 通信的源端口,源主机 IP 地址,目标端口,目标主机 IP 地址,注意,由于 TCP 通信管道是双向的,这意味着,srcport 可能是你托管机房中的 SSH 服务器的端口 22;也可能是你的 SSH 客户端的临时动态端口;需要根据具体情况赋值(取决于你要查看的是那个方向上的流量),其它三个关键字也是同理;
*****粗体关键字 addr_family 的取值只能有2种: “ip” 或 “ip6”,分别对应 IPv4 与 IPv6
=================================
【常用的显示过滤表达式】
仅显示带有目标IP层广播地址的数据包
ip.dst==255.255.255.255
仅显示带有目标链路层广播地址的数据包
arp
在显示过滤表达式中,逻辑运算符 == 等同于 eq
但是需要注意,使用 eq 时,前后的比较值必须有空格,而 == 不需要与前后的比较值留空格
( and 与 && 也是同理)
例如
ip.src eq 192.168.10.0/24 and ip.dst eq 192.168.10.0/24
等同于
ip.src==192.168.10.0/24&&ip.dst==192.168.10.0/24
等同于
ip.src == 192.168.10.0/24 && ip.dst == 192.168.10.0/24
上面是仅显示局域网中主机(工作站)与主机之间,或者主机与内网服务器(以及网关)之间的通信流量,不包含
从内网到外部网络以及到Internet的通信流量,这对处在“混杂模式”工作状态的网卡,用来检测内网主机之间的扫描,攻击流量(例如ARP欺骗),有一定的帮助
仅显示“带有特定的发送端建议接收端设置的接收窗口大小值的数据包”
tcp.window_size == 64239
这个表达式会匹配在数据包列表的 Info 字段的所有 Win=64239 的数据包
下面这个表达式用来捕捉“冲击波”蠕虫病毒产生的网络通信流量,它利用的是 RPC 协议的漏洞:
dst port 135 and tcp port 135 and ip[2:2]==48
Welchia 蠕虫同样利用 RPC 协议的漏洞,但是我们有更好的检测这只蠕虫的捕捉表达式:
icmp[icmptype]==icmp-echo and ip[2:2]==92 and icmp[8:4]==0xAAAAAAAA
我们来分析一下该表达式的语义,它搜索长度为92字节的 icmp echo request
(ICMP 回显请求)数据包,而且该ICMP数据包的有效载荷起始部分为连续4字节长的16进制值0xAA,而这就是当Welchia 蠕虫尝试危害一个系统前的特征
*****许多蠕虫尝试通过与其它主机上的 135,445,1433 端口建立连接,来进行传播,
下面这则捕捉过滤表达式,可以检测绝大多数类型的蠕虫,因为它可以捕捉那些来自本地局域网中的目标端口为 135,445,1433 的 TCP SYN 数据包(请求连接,SYN 标识位的值不为 0 )
dst port 135 or dst port 445 or dst port 1433 and tcp[tcpflags] & (tcp-syn) != 0 and tcp[tcpflags] & (tcp-ack) = 0 and src net 192.168.0.0/24
是系统管理员或运维工程师的童鞋,可以用上面介绍的三则捕捉过滤表达式,来检测你的局域网中是否有机器感染了蠕虫病毒,而且正在尝试进行传播,感染其它机器
还有一件事需要注意,如果你用 SSH 远程连接到服务器(包括 Linux 下的 OpenSSH 以及 windows 下的 3389 终端),并且在服务器上运行 wireshark ,那么 wireshark 会通过检测“环境变量”来智能的过滤掉你与服务器通信的流量,这里过滤的意思是不显示或不捕捉,而非防火墙那样阻挡数据包;
下面列出这些 wireshark 可能会探测的环境变量,并且给出相应的“默认过滤”表达式;如果你想要 wireshark 在服务器上捕捉或显示你与服务器的远程通信流量,只需要将这些表达式中的 not 关键字移除即可,
其中,
*****粗体关键字 srcport srchost dstport dsthost
需要分别替换成你的 SSH 通信的源端口,源主机 IP 地址,目标端口,目标主机 IP 地址,注意,由于 TCP 通信管道是双向的,这意味着,srcport 可能是你托管机房中的 SSH 服务器的端口 22;也可能是你的 SSH 客户端的临时动态端口;需要根据具体情况赋值(取决于你要查看的是那个方向上的流量),其它三个关键字也是同理;
*****粗体关键字 addr_family 的取值只能有2种: “ip” 或 “ip6”,分别对应 IPv4 与 IPv6
=================================
【常用的显示过滤表达式】
仅显示带有目标IP层广播地址的数据包
ip.dst==255.255.255.255
仅显示带有目标链路层广播地址的数据包
arp
在显示过滤表达式中,逻辑运算符 == 等同于 eq
但是需要注意,使用 eq 时,前后的比较值必须有空格,而 == 不需要与前后的比较值留空格
( and 与 && 也是同理)
例如
ip.src eq 192.168.10.0/24 and ip.dst eq 192.168.10.0/24
等同于
ip.src==192.168.10.0/24&&ip.dst==192.168.10.0/24
等同于
ip.src == 192.168.10.0/24 && ip.dst == 192.168.10.0/24
上面是仅显示局域网中主机(工作站)与主机之间,或者主机与内网服务器(以及网关)之间的通信流量,不包含
从内网到外部网络以及到Internet的通信流量,这对处在“混杂模式”工作状态的网卡,用来检测内网主机之间的扫描,攻击流量(例如ARP欺骗),有一定的帮助
仅显示“带有特定的发送端建议接收端设置的接收窗口大小值的数据包”
tcp.window_size == 64239
这个表达式会匹配在数据包列表的 Info 字段的所有 Win=64239 的数据包
仅显示TCP头部中标志字段中的SYN与ACK位被“置位”(设置为1)的数据包
tcp.flags.syn == 1 and tcp.flags.ack ==1
仅显示TCP头部中标志字段中的PSH与ACK位被“置位”(设置为1)的数据包
tcp.flags.push eq 1&&tcp.flags.ack eq 1
一种标识由 windows 主机发送和接收的数据包的办法
smb || nbns || dcerpc || nbss || dns
检测本地或者内网中是否存在冲击波蠕虫病毒(Sasser worm)的方法
ls_ads.opnum==0x09
仅显示UDP(用户数据报)的有效载荷起始处包含 0x81 0x60 0x03 这3个字节序列的任意数据包,(每字节,如0x81,占8位)
并且跳过占8个字节的UDP头部,也就是说,从第9个字节开始计算,总长度为3字节的 81 60 03 字节序列,
注意这3个字节序列的值仅意味着16进制表示法。(用于匹配本地的,非开放式的分组协议)
udp[8:3]==81:60:03
类似的还有
eth.src[4:2]==78:e9
在上面这个例子中,将从以太网 MAC 源地址的第5位开始计算,总长度为2字节,并且匹配 78 e9 字节序列的数据包,
例如,源 MAC 地址为 00:00:29:4c:78:e9 的数据包将被显示
也可以通过使用匹配操作符,来搜索出现在一个字段或协议的任何位置的特征字符,例如,
仅显示在 udp 头部,或者其有效载荷的任何位置处,包含3个特定的字符序列: 0x81,0x60,0x53 的数据包
udp contains 81:60:03
仅显示 SMTP(端口25)与 ICMP 协议相关的流量(邮件交换,与收发电子邮件相关的流量)
tcp.port eq 25 or icmp
仅显示“TCP 缓冲区已满,发送方指示接收方停止发送数据”的数据包
tcp.window_size == 0 && tcp.flags.reset != 1
使用下面这个“分片“过滤表达式,可以仅显示 MAC 地址的厂商标识符部分(OUI),你可以通过指定特定 OUI 来显示来自相关设备制造商的数据包,例如只显示和
DELL 机器相关的流量:
eth.addr[0:3]==00:06:5B
通过使用正则表达式,匹配操作符使得搜索数据包的应用层文本字符串和字节序列成为可能,这需要使用 Perl 语言的正则表达式语法,
注意,该功能依赖于 libpcre 库,需要安装
仅显示 HTTP 请求的 URI 中(完整 URI = GET请求头的值 + HOST 请求头的值),其字符串以 "gl=se" 结尾的数据包
注意此处的美元符号,不属于请求 URI 的一部分,它是 PCRE 匹配的字符串结束标记
http.request.uri matches "gl=se$"
常见的语法陷阱
要过滤掉(来自或去往 10.43.54.65 的数据包) ,你可能会使用
ip.addr != 10.43.54.65 ,但这个表达式不能达到你预期的效果
应该使用下面的过滤表达式:
! ( ip.addr == 10.43.54.65 )
或者
! (ip.src == 10.43.54.65 or ip.dst == 10.43.54.65)
注意,这个例子会“显示”与 10.43.54.65 相关的 arp 广播流量
其它 IP 同样道理,例如
! ( ip.addr == 192.168.1.30 ) && !arp
将过滤掉与192.168.1.30相关的任何流量,并且过滤掉任何 IP 地址的 arp 广播流量
*****假设你要找出任何网页在线播放 flash 视频的数据包,使用下面的表达式,注意,该表达式仅适用于那些 swf 视频地址直接曝露在浏览器请求的 URI 中的数据包,
如果视频地址通过 web 应用程序根据提交的查询字符串“动态生成”,那么下面的表达式或许不能达到你预期的效果:
http.request.uri contains "flv" or http.request.uri contains "swf" or http.content_type contains "flash" or http.content_type contains "video"
对于那些在线播放的“流媒体”视频,更常见的做法是服务器将视频分成很多小“块”传送,每“块”的大小不超过 1 MBytes,在一个前导的 HTTP 响应中首先给出当前要传送的“视频块”大小信息,然后再将这个“视频块”划分成多个长度为 1506 Bytes (这个大小已经达到当前链路层的 MTU 上限),的重新组装的 TCP 分段,
通过每发2~3个这种分段,客户端回送一个长度 50 Bytes 的 ACK 分段,如此重复数十次,才能将一个“视频块”完整的传递到客户端,此时客户端的浏览器插件,
例如 adobe shockwave flash 播放器,就可以播放(需要先解码)这部分“已缓冲”的视频块,
在用户观看这段视频内容的期间,浏览器继续请求下一个视频块,
当然,对于总长度较小的视频以及拥有较大出口带宽的客户端,也可能连续接收和缓存多个视频块,这就是我们看到播放器进度条的缓冲部分一次就走到几乎最右侧的原因;
由于视频服务器上的 web server 会将这种“视频块”的 MIME 类型指定为 application/octet-stream 并包含在携带该视频块统计信息的前导 HTTP Content-Type 响应头中发送,因此,我们只需在 wireshark 的显示过滤表达式中添加这个关键字,就可以捕获这种分块传输的流媒体视频的前导 HTTP 响应包:
http.content_type contains "application/octet-stream"
并且,由实际组成该视频块的后续 “8位字节流”(octet-stream)格式的 TCP 分段,每一个都填满了当前链路层的 MTU 上限(1506 Bytes),因此,下面这个过滤表达式,可以捕捉到实际的流媒体数据包:
frame.len==1506
当然,并非只有流媒体能填满链路层 MTU 上限,所以,你可以通过 逻辑 AND 操作符,在后面添加视频服务器的 IP 或域名来限定
仅显示包含特定“缓存控制”风格的 HTTP 响应:
http.cache_control != "private, x-gzip-ok="""
上面这个例子将显示服务器发送的所有“非 google 风格”缓存指示的 HTTP 响应,这个不太好理解,有兴趣的童鞋可以自行测试,
下面这个表达式有相同的效果,但是更加复杂:
(((((http.cache_control != "private, x-gzip-ok=""") && !(http.cache_control == "no-cache, no-store, must-revalidate, max-age=0, proxy-revalidate, no-transform, private")) && !(http.cache_control == "max-age=0, no-store")) && !(http.cache_control == "private")) && !(http.cache_control == "no-cache")) && !(http.cache_control == "no-transform")
先不论你是否熟悉 HTTP 协议中,和文档的缓存策略相关的内容,但至少通过这个例子可以看出,要通过 逻辑 AND(&&) 连接后续的否定表达式,则逻辑非(!)需要放在前面,且用括号将表达式括起来,不能使用类似 != 的错误语法
*****根据 HTTP 响应的状态码来过滤某些特定类型的数据包:
#404: page not foundhttp.response.code == 404 #200: OKhttp.response.code == 200
第一个过滤表达式仅显示“404错误,找不到页面”的 HTTP 响应包
第二个过滤表达式仅显示“200,OK”的 HTTP 响应包
*****根据 HTTP 请求的方法类型来过滤某些特定类型的 HTTP 请求包
http.request.method == "POST" || http.request.method == "PUT"
上面这个例子中,仅显示 HTTP POST 方法(用于提交用户输入的查询字符串或者 HTML 表单数据)或者 HTTP PUT 方法(用于向服务器上传文档资源)的 HTTP 请求包
*****根据 HTTP 请求或者响应的“内容类型”(Content Type)头部,来过滤 HTTP 请求包
http.content_type[0:4] == "text"
上面这个例子中,仅显示 HTTP Content Type 头部,以字符串“text”开头的数据包,注意,这里的 [0:4] 代表,从第0个字节开始计算,总长度为4字节的字符串
http.content_type contains "javascript"
上面这个例子中,仅显示内容类型为 javascript 的数据包,可以用来找出那些带有 javascript 脚本,即将或者已经被浏览器本地渲染和加载的 HTML 页面
*****仅显示内容类型以 “p_w_picpath” 开头的 HTTP 请求或响应包
http.content_type[0:5] == "p_w_picpath"
上面这个例子中,将会匹配 MIME 类型为 p_w_picpath/(gif|jepg|png|etc) 的数据包,实际上就是用来检测浏览器是否收到包含这些图片资源的 HTML 页面
来自:
https://blog.51cto.com/shayi1983/1558161
(DVOL本文转自:中国DV传媒 http://www.dvol.cn)

